Blog
Arvados 3.1 Release Highlights
Since the release of Arvados 3.0 last November, we’ve continued refining the entire platform to add features and make it nicer for everyone to use, whether you’re writing workflows, analyzing results, or administering a cluster. Today we’re happy to announce the release of Arvados 3.1.0 and share with you some of the biggest new features in it.
Support for AMD ROCm Workflows
Three years ago, Arvados 2.4 introduced support for workflows and containers that use NVIDIA CUDA. Arvados 3.1 adds support for AMD ROCm GPU work alongside that. If you’ve written or used an NVIDIA CUDA workflow before, everything...
Since the release of Arvados 3.0 last November, we’ve continued refining the entire platform to add features and make it nicer for everyone to use, whether you’re writing workflows, analyzing results, or administering a cluster. Today we’re happy to announce the release of Arvados 3.1.0 and share with you some of the biggest new features in it.
Support for AMD ROCm Workflows
Three years ago, Arvados 2.4 introduced support for workflows and containers that use NVIDIA CUDA. Arvados 3.1 adds support for AMD ROCm GPU work alongside that. If you’ve written or used an NVIDIA CUDA workflow before, everything will feel very familiar. Workflow steps just need to declare they want an AMD GPU with particular hardware specifications and a minimum version of ROCm. Arvados records these as runtime constraints of the container request, and Crunch will dispatch the container to a node that can support it. Arvados continues to support your most modern and demanding workflows while handling the details of dispatch automatically for users.
With this change, API attributes and configuration settings that previously referred to “CUDA” now refer to “GPU” generally. Container requests specify which kind of GPU they want in the gpu.stack runtime constraint. When clients submit container requests to the API server, it will automatically translate cuda constraints to gpu as needed, so Arvados 3.1 still supports those clients without any change. If you have other custom client code, or want to learn more about these changes, our upgrade notes have more information about these changes.
Workbench Optimizations
As always, we’re refining Workbench to make common tasks faster and easier for all users. We put a lot of effort into optimizing the rendering code for common Workbench components like data listing tables and navigation trees. Arvados 3.0 improved Workbench’s performance by optimizing the Arvados API calls it makes. Arvados 3.1 continues that work by refining Workbench’s internal data structures and rendering routines. Thanks to this, Workbench should feel snappier and more responsive for everyone using it.
Workbench now lets you resize the right-hand details panel. It also remembers the sizes that you set for both that and the left-hand navigation panel, and restores to that size any time you open one again. This lets you set sizes that work best for your client and data, and then eliminates the need to fuss with them afterwards.
Richer Data Management in Command-Line Tools
We took care to make sure all our command line tools that write data like arv-put, arv-copy, and arvados-cwl-runner give you full control over the data you’re storing in Arvados at every step of the process. All of them now have consistent options to specify collection storage classes and replication level. arvados-cwl-runner still has its dedicated option to set storage classes for intermediate workflow results too. If you don’t set your own storage classes, they properly fall back to using your cluster’s default storage classes rather than a hardcoded value.
We also improved the ergonomics of arv-copy by having it check settings.conf for cluster credentials if it can’t find a cluster-specific configuration file. This way, you don’t have to write duplicate configuration for the common case where you’re regularly copying data to or from the cluster you use most often.
And More
Arvados 3.1 also includes bug fixes across the stack; new tools to make deployment easier; and some back-end changes to support more exciting features in future releases. If you want all the nitty-gritty, that’s in our full release notes. Either way, we hope you enjoy the improvements in Arvados 3.1.
Arvados 3.0 Release Highlights
The whole Arvados team is thrilled to announce the release of Arvados 3.0.0. This is a major release with many significant improvements that we’ve been working on throughout this year while delivering smaller, less disruptive changes in Arvados 2.7 series of releases. With so much cool new stuff, we wanted to take this opportunity to highlight changes that most users will see and benefit from immediately.
New Workbench Project View
The project view has been completely revamped to streamline your work and use the space to show you more information more relevant to you. The project name appears at...
The whole Arvados team is thrilled to announce the release of Arvados 3.0.0. This is a major release with many significant improvements that we’ve been working on throughout this year while delivering smaller, less disruptive changes in Arvados 2.7 series of releases. With so much cool new stuff, we wanted to take this opportunity to highlight changes that most users will see and benefit from immediately.
New Workbench Project View
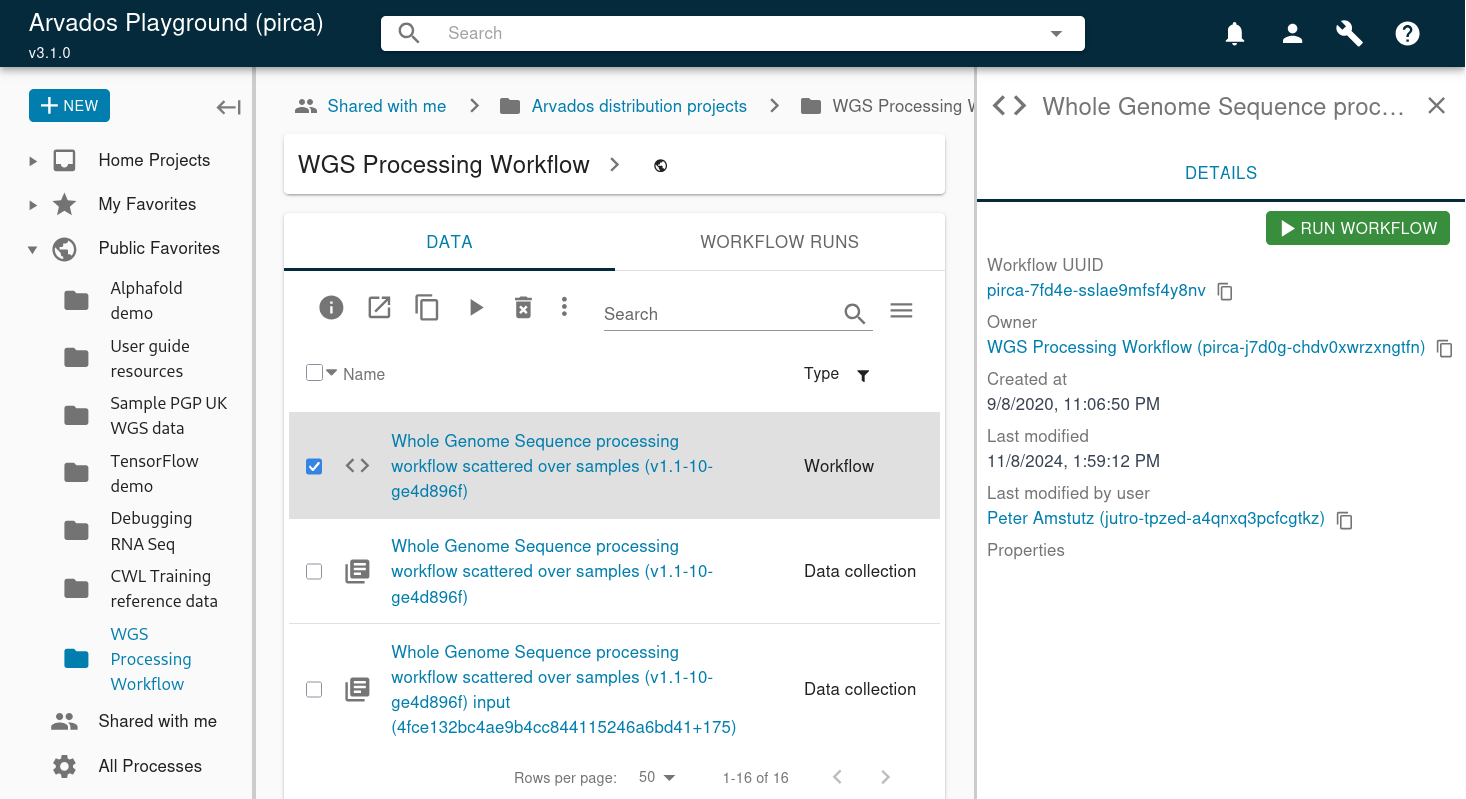
The project view has been completely revamped to streamline your work and use the space to show you more information more relevant to you. The project name appears at the top of the page, followed by an action toolbar with all the operations you might want to perform. If you’re looking for more information about this project, you can pull down the chevron to see the full project description (which can include HTML) and metadata properties.
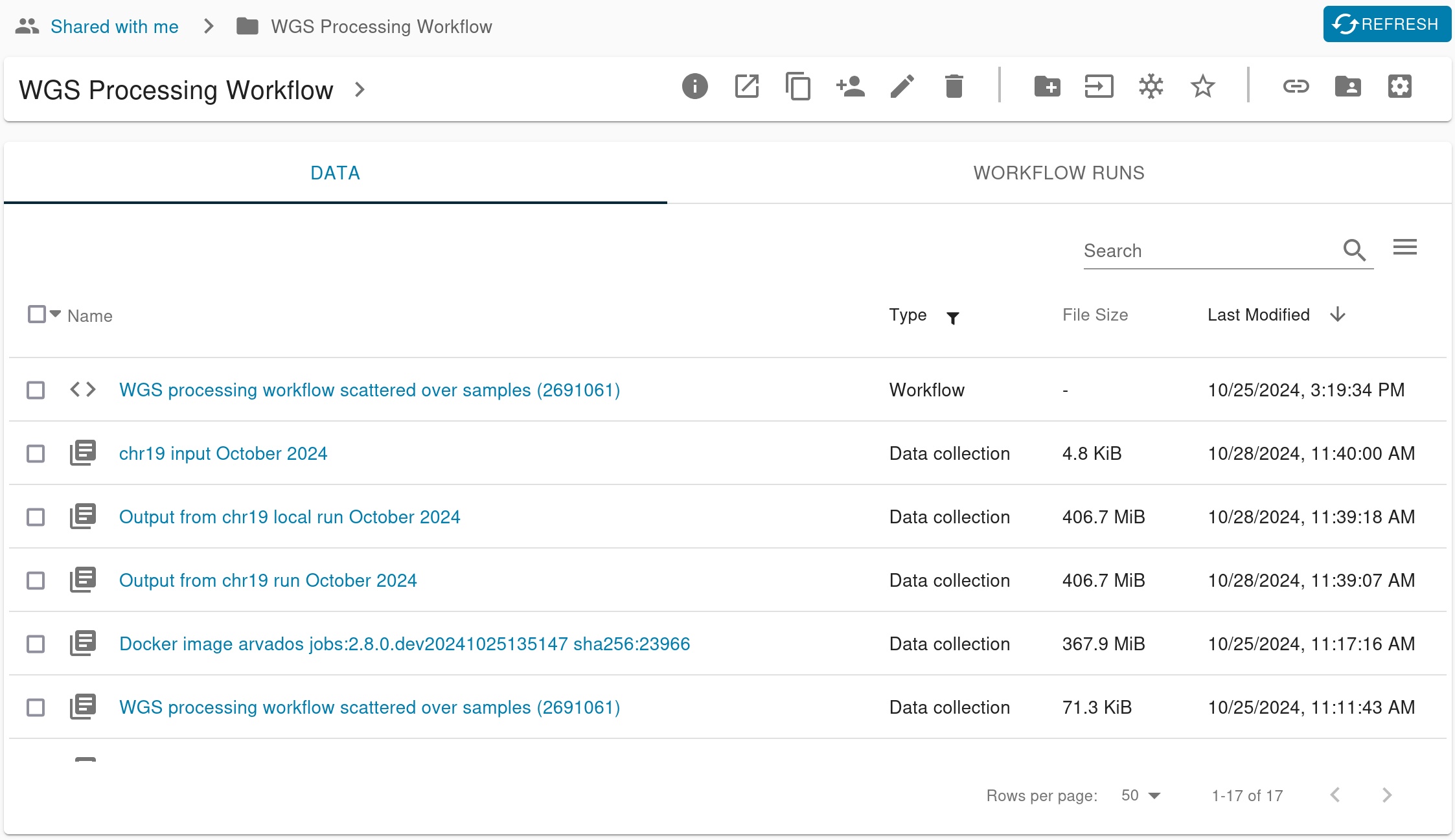
Below that, the contents listing is now split into two tabs: Data and Workflow Runs. The Data tab lists the project’s collections and workflow definitions. The Workflow Runs tab lists all the workflow runs under this project. Based on feedback from users, we think this will make it easier for people to focus on their common tasks: launching workflows, checking progress, and reviewing results. Whatever you’re looking for, you should be able to find it faster now that workflow runs and their outputs aren’t weaved together chronologically. It also means the listing columns are more relevant and focused: the Data tab shows information relevant to inputs and results, while the Workflow Runs tab shows another set relevant to ongoing work.
You can still sort and filter the listings just like before, so you can still limit the Data tab to showing only output collections, on the Workflow Runs tab to show processes with the oldest first. None of that functionality is going away. Instead you can think of the tabs as a sort of “pre-filter” on the listing.
Launch Workflows With Ease
We’ve made improvements to all the different interfaces you use to run a workflow so you have the information you need at your fingertips without cross-referencing resources. After you select your workflow, the dialog shows the full workflow description, which can include instructions about how to select inputs or set parameters.
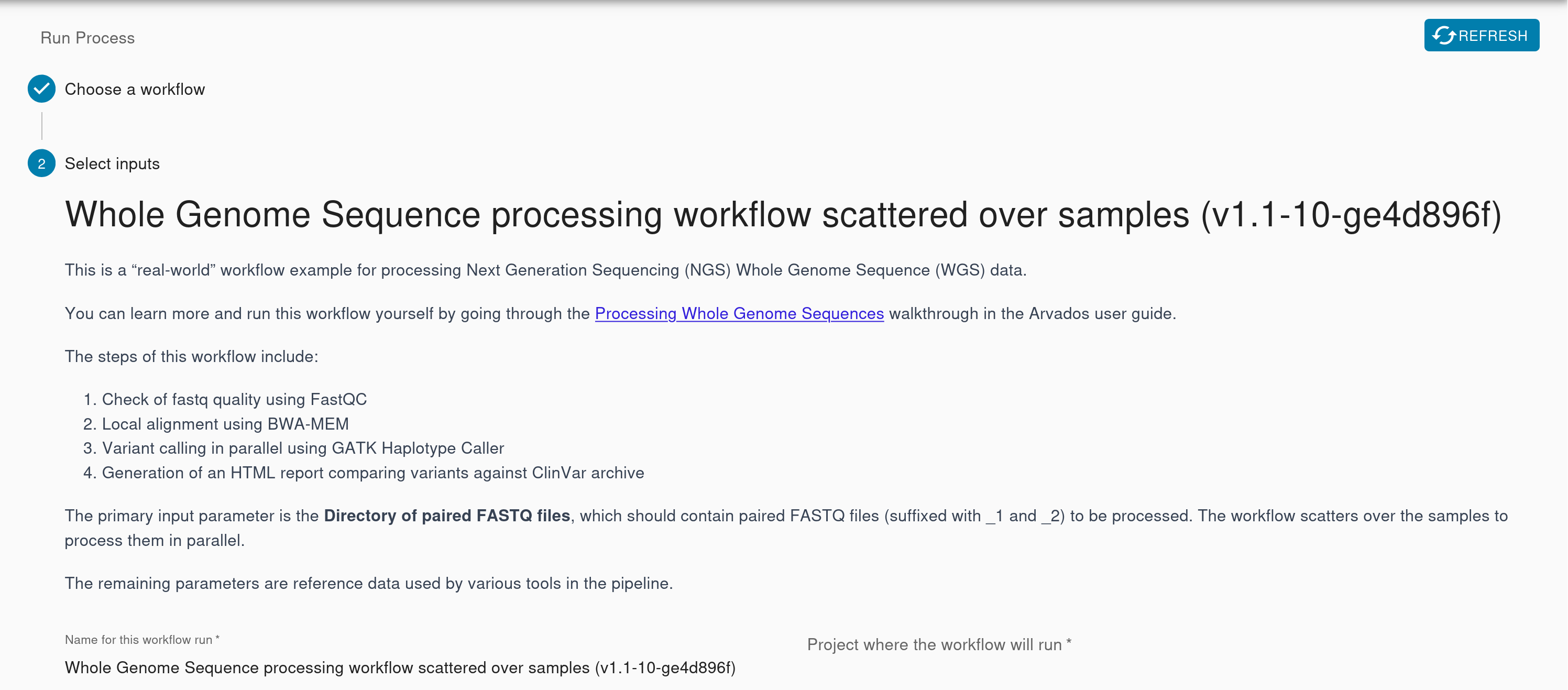
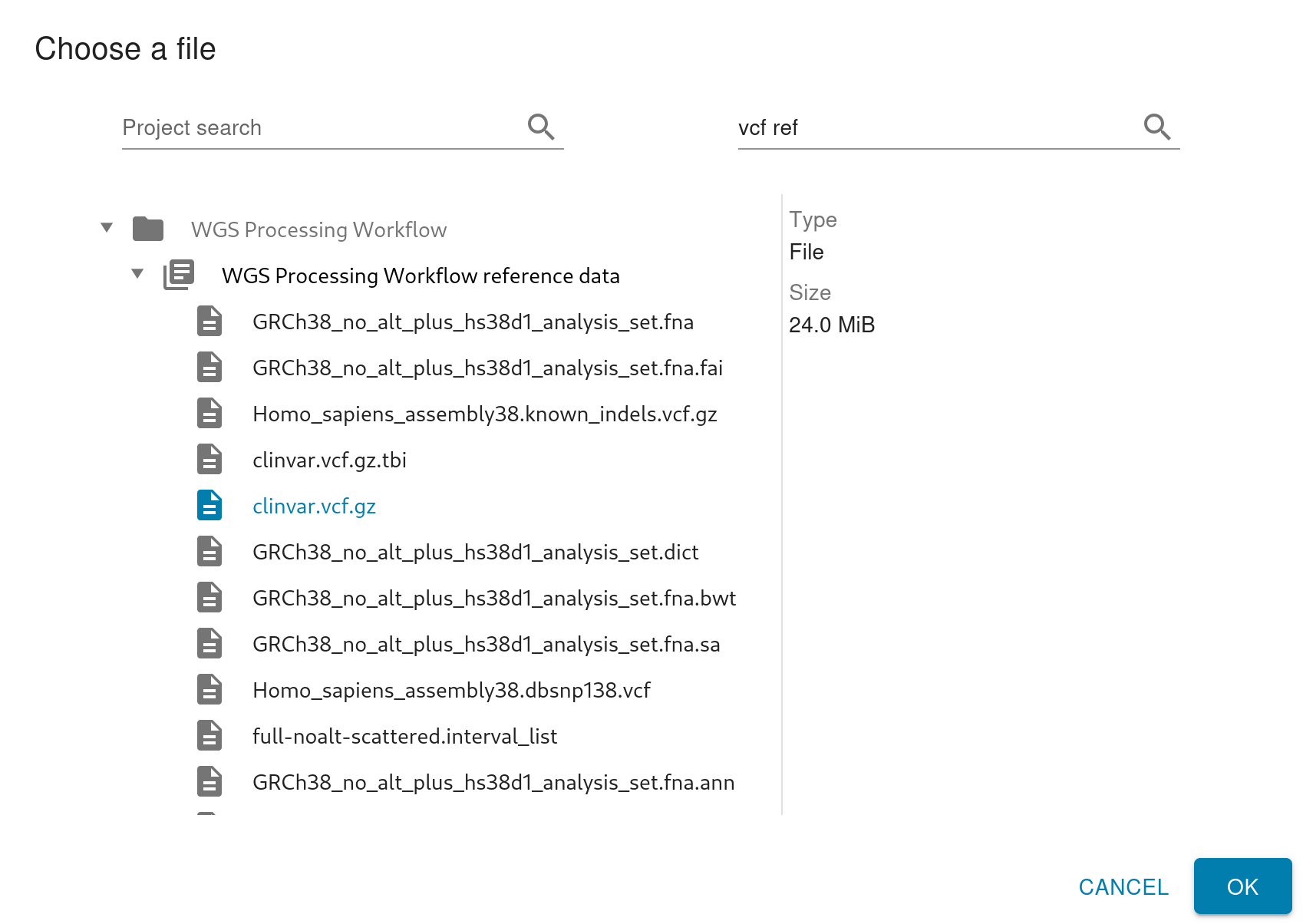
The input selection dialog always shows the parent project containing your selection. If you search for a project, you won’t get a flat listing of results anymore. Instead, the results will show you what projects those collections live in. To help with that even further, you can select any item to see more information about it in the right pane, even if it’s not the type of object you need to select for this input. This makes it easier to find and select the item you need from this dialog.
Workflow secret inputs are now fully supported. You can register workflows with secret inputs, launch them from Workbench, and have that data handled securely throughout.
Once you’ve started your workflow, if you’re using Arvados’ cloud dispatcher, the Logs pane will now give you updates about where your process is in the queue or the bootstrapping process. This gives users more information about what kind of turnaround time to expect. Future versions of Arvados may provide this information for other Crunch dispatchers.
Once your workflow is completed, you can go to the Resources pane of any step to get a report with more information about how that process used its hardware resources like CPU, memory, and network. If you’ve used the crunchstat-summary report before, this is the same report, but now it’s automatically generated when the workflow is run, and made available directly through Workbench. This makes it easier for users to diagnose resource problems in their workflow definitions and make appropriate adjustments.
Performance Improvements
Under the hood, we’ve refined Workbench’s network requests to make them more efficient, so it gets the data it needs with fewer round trips. This makes searching and browsing in Workbench more responsive throughout whether you’re browsing projects, launching a workflow, or reviewing results.
Some of those speed improvements happened directly in the API server. Text searches now ignore identifier columns like UUIDs and portable data hashes, so they return more relevant results faster. API listings can now include more referenced resources. Clients like Workbench can request all the information they need in a single request.
Data management is faster thanks to various performance improvements across Keep services. The core Keepstore service has a new streaming architecture that can start sending a data block to clients before it’s fully read, reducing time to first byte and other key performance metrics. Keep still preserves integrity by terminating the connection early if the data block does not match its checksum, so clients still have that guarantee without implementing their own checks.
Consumers like keepproxy and keep-web now cache more data to make fewer network requests. They also make better use of the replace_files parameter to update collections to reduce the amount of data that needs to be transferred for common changes to data sets.
Better Documentation
The reference documentation for the Python and R SDKs is now much more complete with full descriptions for every API method, parameter, and result. This documentation is generated from information in the Arvados API “discovery document,” so we can incorporate it into other SDKs’ documentation in the future.
The documentation is also streamlined because we have removed obsolete APIs from both Arvados itself and the Python SDK in Arvados 3.0. We’ve also reorganized the Python SDK so private support code is clearly marked and not covered in the reference documentation. Thanks to all this, the documentation is much more focused on the interfaces you should use, with less cruft in the way.
That’s Not All
Arvados 3.0 has been in the works through much of the year and we’re really excited for you all to start using it. Because this is such a big release, administrators should make sure to check out the upgrade notes for important information about how to upgrade their clusters. Anyone looking for even more detail about what’s new can check out our full release notes.
If you’re not using Arvados yet, the new version is already running on our Arvados Playground, where anyone can make an account and try it out. If you’d like help installing or upgrading your own cluster, Curii has consulting and support services that can help. Get in touch with us at info@curii.com.
Scientific Workflow and Data Management with the Arvados Platform
I recently gave a talk at the recent Bioinformatics Open Source Conference (BOSC 2022) entitled: “Scientific Workflow and Data Management with the Arvados Platform”.
In making that talk, it struck me that this topic would also make a good blog post to describe my thoughts on the importance of workflow and data management and how we have incorporated such capabilities into the Arvados platform.
Reproducibility and Workflow Management
Reproducible research is necessary to ensure that scientific work can be understood, independently verified, and built upon in future work. Replication, validation, extension and generalization of scientific results is crucial for scientific progress. To be able to confidently reproduce results, you need a complete record of computational analysis you have done.
One of the major goals of the Arvados Project is to create a 100% open-source platform designed to help users automate and scale their large scientific analyses while ensuring reproducibility. We want users to be able to easily repeat computations, reproduce results, and determine the provenance of data (i.e. tracking any data from raw input to final result, including all software used, code run, and intermediate results.)
Some examples of reproducibility issues include:
- “We’re working in the cloud. Everyone has access to the S3 bucket, but to find anything you have to go ask Jane who has the whole directory tree in her head”.
- “I tidied up the project files a bit, and now the workflow stopped working with ‘File not found’ error.”
- “I re-ran the workflow but I’m not getting the same results, I can’t tell what changed.”
Problems with Conventional File Systems and Object Storage
When you store data directly on a file system or object storage, you cannot reorganize data without breaking all old references to data and you cannot attach metadata to datasets. S3 supports tags, but tags are extremely limited and cannot be used to query for specific objects in the S3 API. Permission management is mostly per-file, and difficult to manage. The common workaround is to give everybody access to everything, and hope nobody deletes anything important by accident.
When you run scientific workflows on top of conventional systems like this, you inherit all of their problems.
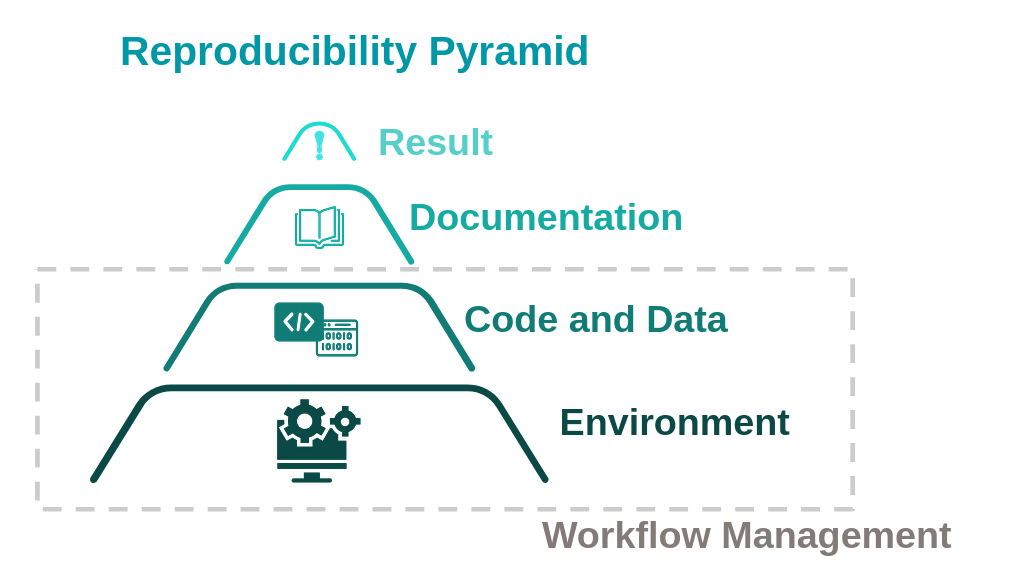
Figure 1: Diagram of multiple levels needed to produce reproducible results. Graphic modified from the work of Code Refinery
A large part of reproducibility involves “Workflow Management”. As illustrated in Figure 1, reproducible results rely on multiple levels that each contribute to reproducibility. The first two levels involve both the reproducibility of the code and of the environment. Combined, the management of both code, data, and environment can fall within the larger category of “Workflow Management” .
Workflow Management requires:
- keeping a record of workflow execution
- keeping track of input, output, and intermediate datasets
- keeping track of the software (e.g. Docker images) used to produce results.
Workflow Management inherently includes data management. Requirements of robust data management ideally include that all data should be identifiable at a specific point in time and/or by content.
The related data should be
- findable both through naming conventions, and searchable attached metadata
- associated with robust identifiers that don’t change when data is reorganized
- versioned to keep track of all data change
- secure and shareable
Arvados integrates data management (“Keep”) together with compute management (“Crunch”), creating a unified environment to store and organize data and run Common Workflow Language (CWL) workflows on that data. Major features of Arvados were designed specifically to efficiently enable computational reproducibility and data management.
Arvados File System and Collections
The Arvados content-addressable storage system is called Keep. Keep ensures that workflow inputs and outputs can always be specified and retrieved in a way that is immune to race conditions, data corruption, and renaming.
Keep organizes sets of files into a “collection”. A collection can have additional user metadata associated with it in the form of searchable key-value properties, and records the history of changes made to that collection. Data uploaded to Arvados is private by default, but can be shared with other users or groups at different access levels. To store data in a collection, files are broken up into a set of blocks up to 64 megabytes in size, which are hashed to get an identifier which is used to store and retrieve the data block. Collections can be then referenced by this content address (portable data hash) so later reorganization of input and output datasets does not break references in running workflows.
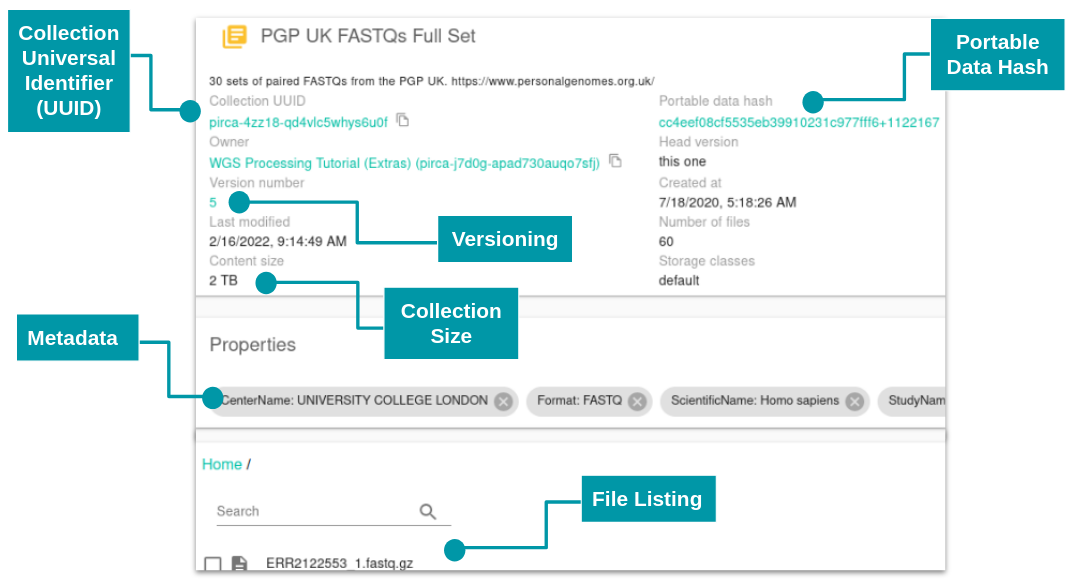
Figure 2: A ~2TB Arvados collection viewed in Workbench 2. The universal identifier (UUID), portable data hash (PDH), collection size, version, metadata and file listing are easily accessible.
An added benefit of the Keep is that it provides de-duplication, as the same data block can be referenced by multiple collections. This also means that it is cheap to copy and modify collections, as only the block identifiers need to be copied and not the actual data. You can learn more about how keeps works at this blog post, A Look At Deduplication In Keep.
When a workflow is run in Arvados, the entire workflow execution is stored in collections. This includes inputs, outputs, steps, software (Docker images), and logs allowing for full traceability of your executed workflows. Arvados can check if an identical step in a workflow has already been run and then reuse past results, so re-running a workflow where only certain steps have changed is quicker and more efficient. Without automated features to support this optimization, informaticians are tempted to make such decisions manually, a practice which is error-prone and therefore often wastes more time than it saves.
Workflows and Standardization
Storing data in standardized formats is extremely valuable. It facilitates sharing with others, using the same data with different software, and the ability to use old datasets. Similarly, standards for writing workflows are extremely valuable. A standard for sharing and reusing workflows provides a way to describe portable, reusable workflows while also being workflow-engine and vendor-neutral. Arvados supports the Common Workflow Language (CWL), an open standard used and supported by many organizations. It facilitates sharing and collaboration, has multiple execution engines, and a commitment to a stable definition.
Using Metadata and Freezing Projects
Arvados administrators can set up a formal metadata vocabulary definition, enforced by the server. In the user interface, users are given a list of predefined key/value pairs of properties. For more information, visit the documentation.
Starting in Arvados 2.4.3, Arvados now automatically records git commit details for workflows. When a CWL file located in a git checkout is executed or registered with --create-workflow or --update-workflow, Arvados will record information about the git commit as metadata for the workflow and use git describe to generate a version number that is incorporated into the Workflow name.
Starting in Arvados 2.5 you can freeze a project. A frozen project becomes read-only so that everyone (including the owner and admins) are prevented from making further changes to the project or its contents, including subprojects. This adds a layer of protection so that once a project is “finished” and ready to share with others, it can’t be changed by accident.
Summary
By combining both a data management and compute management system, Arvados enables researchers to analyze and share data while maintaining security and control, keep a record of analysis performed, and attach metadata to data sets to answer questions such as when, where, why and how a data set was collected.
Computing with GPUs: New GPU Support in Arvados 2.4
Arvados 2.4 now supports using GPUs, specifically the NVIDIA CUDA platform. In this blog post, we will show an example of running a TensorFlow machine learning demo on Arvados.
About the GPU Demo
We will be running using a demo that uses TensorFlow. TensorFlow is a free and open-source software platform used for machine learning and artificial intelligence with a focus on neural networks. This TensorFlow demo trains a neural network to create a classifier that identifies handwritten digits. It uses data from a famous dataset, the MNIST handwritten digit dataset, which is a large database of images of handwritten digits. It is a classic “real-world” dataset used by those wishing to learn more about machine learning. Each image is stored as 28x28 pixels (28x28 matrix of grayscale values).

Sample images from the MNIST database (By Josef Steppan - Own work, CC BY-SA 4.0)
The demo has several main steps:
- Load and Preprocess a Training Set: This includes loading in the handwritten digits data, normalizing by 250 and converting the integers to double precision numbers. The data loaded in is already divided into a test and training set.
- Build a Neural Network: In this case, a sequential model is used to create the neural network. The model is created to take in an input of an image (28 x 28) and return the probability that the image is each class (i.e. 0-9).
- Train the Neural Network: The model is trained (i.e.the model parameters are adjusted to minimize the chosen loss function) using the training data.
- Evaluate Accuracy of the Neural Network: The model is then tested on the “test-set”. This means, the model is run to classify images that were not used to train the model. Then the accuracy is calculated on how well the model did on predicting the actual digit in these new images. The classifier is found to have ~98% accuracy on the testing set.
This is implemented using the following TensorFlow script (tf-mnist-tutorial.py) (derived from TensorFlow 2 quickstart for beginners):
Using the model
The ultimate output is a trained and tested neural network model (e.g. the model) that can be used to identify digits from new unclassified images. The model can then be applied to novel input to make classification decisions.
predictions = model(input)
Gives log-odds for each possible digit classification
probabilities = tf.nn.softmax(predictions).numpy()
Converts log-odds to probabilities for each possible digit classification
This can also be written by adding the softmax step into the model itself:
probability_model = tf.keras.Sequential([model,tf.keras.layers.Softmax()])
probabilities = probability_model(input)
With the array of probabilities, one can determine a classification by finding the highest probability of match over a threshold.
Running the Demo on Arvados
Now we wrap the TensorFlow Python script with a Common Workflow Language (CWL) CommandLineTool to specify the Docker image that provides the TensorFlow software environment, the amount of RAM needed, and the GPU requirement. Arvados supports the CWL extension cwltool:CUDARequirement to request nodes with NIVIDA GPUs. This requirement also declares CUDA version and minimum compute capability needed to run your tool, which Arvados will use to select the correct compute environment to run the job. And, that is all that is needed to run your GPU-ready code on Arvados!
cwlVersion: v1.2
class: CommandLineTool
$namespaces:
cwltool: "http://commonwl.org/cwltool#"
requirements:
DockerRequirement:
dockerPull: tensorflow/tensorflow:2.6.0-gpu
ResourceRequirement:
ramMin: 4000
cwltool:CUDARequirement:
# https://www.tensorflow.org/install/gpu
# tensorflow requires CUDA 11.2 and minimum compute capability 3.5
cudaVersionMin: "11.2"
cudaComputeCapability: "3.5"
inputs:
script:
type: File
default:
class: File
location: tf-mnist-tutorial.py
inputBinding:
position: 1
mnist:
type: File
default:
class: File
location: https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
inputBinding:
position: 2
outputs: []
baseCommand: python
The demo and demo output are available on the Arvados playground for easy reference.
Try it yourself!
If you liked this example, feel free to replicate it with a free account on the Arvados playground, or have a look at the documentation for installing Arvados. Alternatively, Curii Corporation provides managed Arvados installations as well as commercial support for Arvados. Please contact info@curii.com for more information.
Debugging CWL Workflows and Tools in Arvados
Arvados 2.2 introduced a new feature that can help to debug your workflows: interactive ssh connectivity to running containers. This presents a good opportunity to provide an overview of debugging patterns and tools for running CWL workflows in Arvados.
This article will describe techniques to help determine why an Arvados workflow isn’t running or is returning unexpected results. This will be done with examples of “broken” code and the use of these techniques to debug them. All the files used are available here for download on Github and can be run on the Arvados playground.
This article assumes knowledge about the basic technical components of Arvados. A video with a technical overview of Arvados is available on Youtube.
Debugging techniques
CWL workflow validation
One of the first steps before running a CWL workflow or tool on Arvados is to validate the CWL code.
arvados-cwl-runner has a --validate command line option which validates CWL document without submitting it to Arvados. The validation ensures that the CWL can be parsed and is semantically correct. As of Arvados 2.3.1, workflow validation also detects circular dependencies in the CWL definition. The check for circular dependencies also happens when the workflow is submitted to Arvados.
As an example, we check the CWL command line tool fastqc_blog_broken.cwl which runs fastqc on an input fastq. An typo has been introduced: the type of the input fastq1 was changed to Files, where it was supposed to be File.
Arvados log files: a failure example
As an example, we submit a workflow that fails during execution, and resolve why it failed by using the logs. The CWL files are available here.
arvados-cwl-runner --project-uuid pirca-j7d0g-esxj0i6rwqci132 --no-wait STAR-index-broken.cwl STAR-index.yml
The failed workflow step can be found on the Arvados playground.
The stderr.txt log file indicates that something is wrong with the memory allocation:
2021-06-16T19:48:26.772909733Z !!!!! WARNING: --genomeSAindexNbases 14 is too large for the genome size=249250621, which may cause seg-fault at the mapping step. Re-run genome generation with recommended --genomeSAindexNbases 12
2021-06-16T19:48:29.376258632Z terminate called after throwing an instance of 'std::bad_alloc'
2021-06-16T19:48:29.376258632Z what(): std::bad_alloc
The crunch-run.txt log file provides additional information about the status of the container execution environment, including the docker container that ran this workflow step.
021-06-16T19:48:15.102948472Z crunch-run 2.2.0 (go1.16.3) started
2021-06-16T19:48:15.102999410Z Executing container 'pirca-dz642-7hc4igolissn5oh'
2021-06-16T19:48:15.103010058Z Executing on host 'ip-10-254-254-84'
2021-06-16T19:48:15.188750604Z Fetching Docker image from collection '2975e1250c18c7a8becb73ddce572480+134'
2021-06-16T19:48:15.206050230Z Using Docker image id 'sha256:8993688148d9178dd5b0076e8924f604074bb4b73b6dab0b163e19db0ada4607'
2021-06-16T19:48:15.206851288Z Loading Docker image from keep
2021-06-16T19:48:16.879249955Z Docker response: {"stream":"Loaded image ID: sha256:8993688148d9178dd5b0076e8924f604074bb4b73b6dab0b163e19db0ada4607\n"}
2021-06-16T19:48:16.879459532Z Running [arv-mount --foreground --allow-other --read-write --crunchstat-interval=10 --file-cache 268435456 --mount-by-pdh by_id /tmp/crunch-run.pirca-dz642-7hc4igolissn5oh.602395099/keep946110334]
2021-06-16T19:48:17.219802403Z Creating Docker container
2021-06-16T19:48:17.324166684Z Attaching container streams
2021-06-16T19:48:17.431854735Z Starting Docker container id 'c33799de8f8333d3387bdbbf317f1be2bfd6afba6d4fd342e11a82ba06a8b62d'
2021-06-16T19:48:17.999107080Z Waiting for container to finish
2021-06-16T19:48:32.260611006Z Container exited with code: 139
2021-06-16T19:48:32.277278946Z copying "/_STARtmp/.keep" (0 bytes)
2021-06-16T19:48:32.277359840Z copying "/core" (510050304 bytes)
2021-06-16T19:48:35.638936137Z copying "/hg19-STAR-index/Log.out" (2993 bytes)
2021-06-16T19:48:35.640508974Z copying "/hg19-STAR-index/chrLength.txt" (10 bytes)
2021-06-16T19:48:35.641215862Z copying "/hg19-STAR-index/chrName.txt" (5 bytes)
2021-06-16T19:48:35.641876382Z copying "/hg19-STAR-index/chrNameLength.txt" (15 bytes)
2021-06-16T19:48:35.642580535Z copying "/hg19-STAR-index/chrStart.txt" (12 bytes)
2021-06-16T19:48:35.643158351Z copying "/hg19-STAR-index/exonGeTrInfo.tab" (1123248 bytes)
2021-06-16T19:48:35.653183835Z copying "/hg19-STAR-index/exonInfo.tab" (573122 bytes)
2021-06-16T19:48:35.657092960Z copying "/hg19-STAR-index/geneInfo.tab" (69585 bytes)
2021-06-16T19:48:35.658543819Z copying "/hg19-STAR-index/sjdbList.fromGTF.out.tab" (632839 bytes)
2021-06-16T19:48:35.663954297Z copying "/hg19-STAR-index/transcriptInfo.tab" (208431 bytes)
2021-06-16T19:48:37.572832098Z Complete
Arvados is configured to use Docker as the runtime engine, and the docker container exited with code 139, which indicates the process was killed by signal 11 (139 - 128 = 11, SIGSEGV). A SIGSEGV is often caused by a code bug such as a null pointer dereference, e.g. after failing to notice that a memory allocation failed.
When using a cloud dispatcher, Arvados uses the cheapest possible node that satisfies the resource requirements to run a specific workflow step. The node type that was used and its specifications (number of cores, RAM, scratch space) is logged in the node.json file. RAM and scratch space are expressed in bytes:
{
"Name": "t3small",
"ProviderType": "t3.small",
"VCPUs": 2,
"RAM": 2147483648,
"Scratch": 100000000000,
"IncludedScratch": 50000000000,
"AddedScratch": 50000000000,
"Price": 0.0208,
"Preemptible": false
}
In this case, a small cloud node type (t3.small) was used, with 2 Gigabytes of RAM.
The CWL tool description in STAR-index-broken.cwl does not list resource requirements. This means that the default value for ramMin is used, which is 256 Mebibytes (2**20). Arvados restricts the container runtime environment to the amount of ram defined by the workflow definition. In this case, with Docker as the container engine, this is implemented via a cgroup that restricts the amount of memory available to the Docker container.
The resource requirements can be changed in the CWL code so that the step is scheduled on a machine with more resources. Note that CWL specifies resource requirements like ramMin in mebibytes:
ResourceRequirement:
coresMin: 2
ramMin: 12000
arvados-cwl-runner --project-uuid pirca-j7d0g-esxj0i6rwqci132 --no-wait STAR-index.cwl STAR-index.yml
With these changes, the step ran successfully.
The node.json log can be used to check that the node used matched the new requirements:
{
"Name": "m5xlarge",
"ProviderType": "m5.xlarge",
"VCPUs": 4,
"RAM": 17179869184,
"Scratch": 200000000000,
"IncludedScratch": 100000000000,
"AddedScratch": 100000000000,
"Price": 0.192,
"Preemptible": false
}
Getting performance and resource usage information
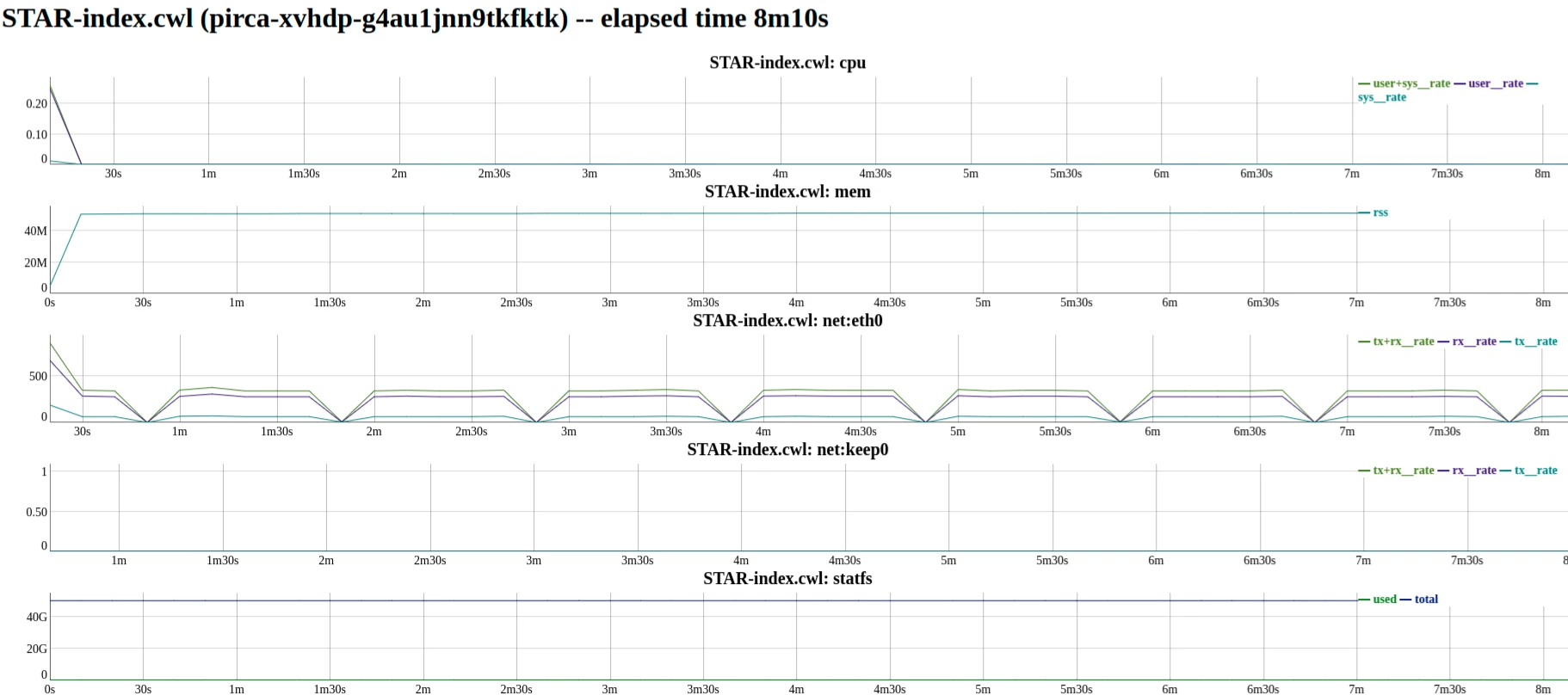
The crunchstat-summary tool can be used to analyze workflow and container performance. crunchstat-summary analyzes the crunchstat lines from the logs of a container or workflow and generates a report in text or html format. Among other information, crunchstat-summary reports the network traffic, memory usage, and CPU usage of tasks.
As an example, we run crunchstat-summary on the job from the previous section to see exactly how much RAM is necessary to run our job.
crunchstat-summary --container pirca-xvhdp-g4au1jnn9tkfktk
The output shows usage for both the workflow runner job as well as for each step in our workflow. In this case, there is only 1 step.
The tail end of the output shows that the CWL requiring too much RAM for this step, and that it can be reduced which may permit the container to be scheduled on a smaller, cheaper instance from the cloud provider.
# Number of tasks: 1
# Max CPU time spent by a single task: 414.22s
# Max CPU usage in a single interval: 169.99%
# Overall CPU usage: 94.14%
# Max memory used by a single task: 6.84GB
# Max network traffic in a single task: 0.27GB
# Max network speed in a single interval: 26.50MB/s
# Keep cache miss rate 0.14%
# Keep cache utilization 100.00%
# Temp disk utilization 2.80%
#!! workflow.json#main max RSS was 6519 MiB -- try reducing runtime_constraints to "ram":7140383129
#!! workflow.json#main max temp disk utilization was 3% of 96189 MiB -- consider reducing "tmpdirMin" and/or "outdirMin"
It is also possible to change the crunchstat-summary output format to html by giving it the --format html argument. Doing so will result in plots of memory and keep utilization over the duration of the job.
crunchstat-summary --container pirca-xvhdp-g4au1jnn9tkfktk --format html >/tmp/charts.html
Debugging Locally Using Docker and Mounted Keep Volumes
With arv-mount, Arvados collections can be accessed using traditional filesystem tools. This allows browsing, opening and reading of data in Keep as one would regular files. By mounting a keep volume, a running docker container can access files in Keep as a shared filesystem. This is often useful when you want to debug the code that is being run by CWL.
Because docker runs as a different user, be sure to use the --allow-other cli option when invoking arv-mount so that Docker can access your mounted keep volume.
docker run -ti -v /localkeepdirectory/keep:/keep YOUR_DOCKER_IMAGE
This can be extremely useful because it allows debugging with the data for the workflow without having to download it all first. When working with large amounts of data, copying it all to a local machine may not be possible, let alone practical.
Additionally, this method makes it possible to use the same docker container used on Arvados, which should help to reproduce the same runtime environment as where the error occurred while running on Arvados.
Connecting to a running container for interactive debugging
New in Arvados 2.2.0 is the ability to get access to a running container and interactively debug your workflow.
In order to get shell access to your container while it is running, you will need access to a machine with OpenSSH and arvados-client installed, and the usual Arvados environment variables set
The cluster administrator will also need to enable container shell access. It is disabled in the default configuration because using container shell access can interfere with the reproducibility of workflows. To enable the feature cluster-wide:
- set Containers / ShellAccess / User: true in the cluster config: see the container shell documentation
- up-to-date Nginx configuration: see “new proxy parameters” in the release notes
Once the prerequisites are met, it is possible to run commands and start interactive sessions:
$ arvados-client shell $container_request_uuid top -bn1 | head
...
$ arvados-client shell $container_request_uuid
root@abcdef1234:~# ls /
...
It is also possible to connect to services inside the container, e.g. debugging/profiling/metrics servers, by forwarding TCP ports:
$ arvados-client shell $container_request_uuid -N -L6000:localhost:6000